


When OpenAI recently announced that one of its models had disproved a long-standing conjecture in discrete geometry, the scientific community took notice. We are entering an era in which AI can solve real open problems that have resisted expert answers for decades. But the excitement raises an important question: why are mathematics and coding the fields where AI is making its most dramatic advances, while life science research remains largely untransformed?
The answer is not about compute, model size, or lack of effort. It is about the nature of the problem itself.
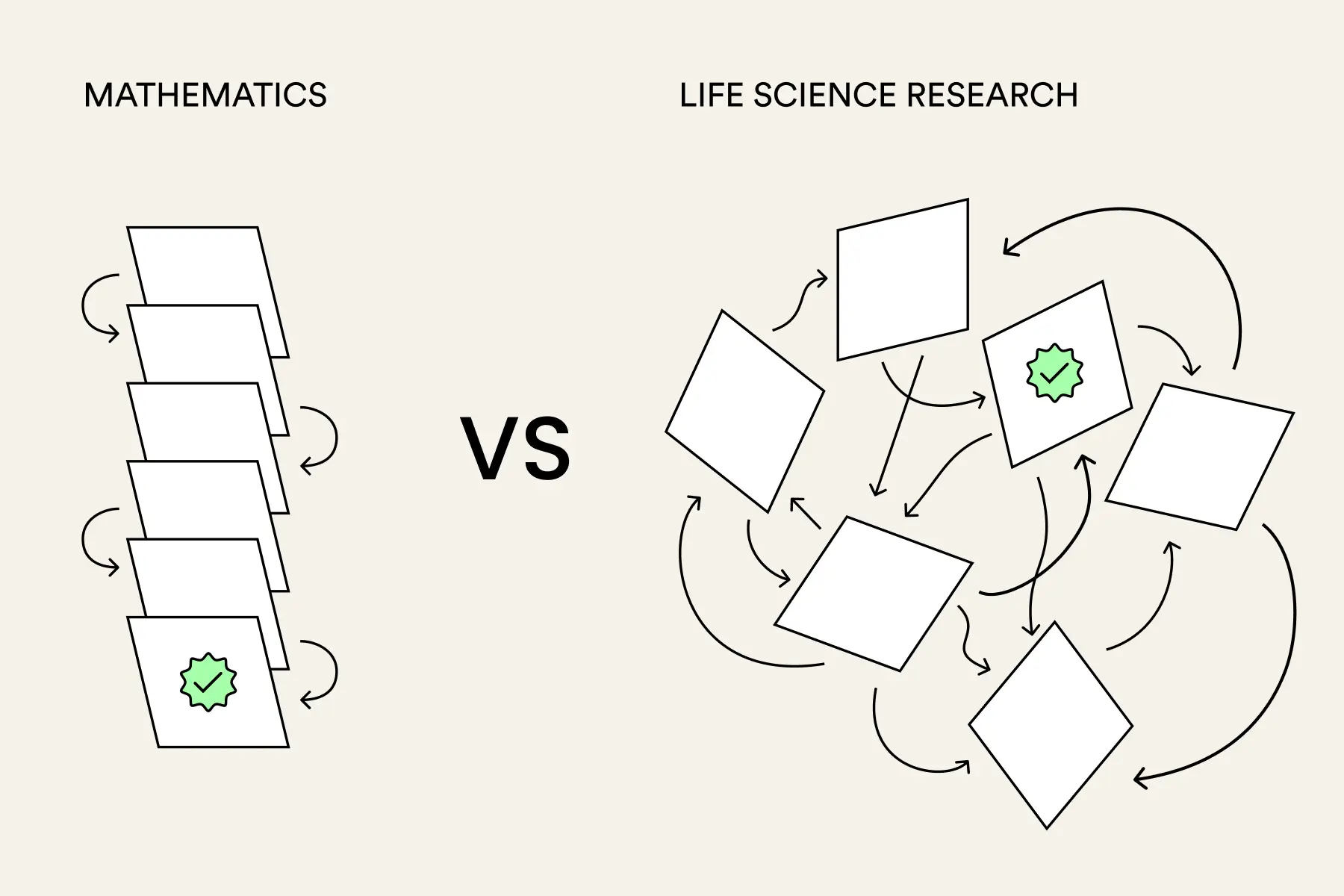
In mathematics, truth is verifiable
In mathematics, once an argument has been written down, the central question is whether it is valid. There is a logical structure to work with. There are set definitions, claims that follow from previous claims, and many steps that can each be examined in a fixed and determinate way. This verifiability is also what makes mathematics and programming so well suited to reinforcement learning, one of the primary engines of recent LLM advancement. The model can check its own work.
Life science is a totally different discipline. A published claim may depend on a specific cell line, reagent, protocol, animal model, patient cohort, statistical choice, or biological context that is never fully specified. A result can be technically correct and still not generalize. It can be statistically significant and biologically meaningless. It can replicate in one laboratory and fail in three others. It can be an important clue, a narrow observation, or an overextended conclusion, and the paper may not distinguish between these possibilities at all.
In mathematics, previous results can be treated as reliable building blocks. In life science, a published result is not automatically a stable premise. This is what makes empirical science so exciting, and sometimes so frustrating.
Life science literature is not a collection of facts
For researchers, reviewers, and R&D teams, this creates a profound challenge. Scientific progress depends on building on prior work, but the literature is a mixture of robust findings, fragile findings, context-dependent findings, incomplete claims, and occasionally incorrect ones. And you cannot tell which is which from the citation count, the abstract, or the journal name.
A finding's validity cannot be assessed from its conclusions alone. It must be interrogated at the level of its construction:
- What has been directly demonstrated, and what was inferred?
- What assumptions were required, and what controls are absent?
- What alternative explanations remain consistent with the data?
- Does the conclusion depend on a particular model system, cohort or assay?
- And beyond any single paper: which findings should become foundations for future work, and which should remain provisional?
Of course, these are questions scientists already ask, but slowly, individually, and at a scale that cannot keep pace with the literature.
Volume compounds the problem. With over 1.5 million biomedical papers published each year, at least half estimated to be irreproducible, and 72% of researchers agreeing there is a reproducibility crisis in their field, the challenge is knowing which parts of the literature can be trusted, in what context, and with what caveats. This is the context in which researchers today work, and while tools that summarize papers are useful, just as tools that search the literature are useful, neither addresses the harder problem of verification.
Prestige has become a shortcut
Because the literature is so large and uneven, researchers rely on proxies. Journal rank, institutional affiliation, citation count, and familiarity with a lab all improve the odds that a result is worth paying attention to. But they are shortcuts, not guarantees, and they shouldn’t be allowed to become substitutes for true verification.
Important work appears outside top journals. Negative results are hard to find. Smaller laboratories produce highly relevant observations that go unnoticed. Meanwhile, highly visible papers can contain weak claims, unsupported interpretations, or conclusions that travel further than the data allow.
For academia, this means good work gets missed and fragile assumptions propagate. In pharmaceutical R&D, the stakes are even higher. Decisions about targets, indications, biomarkers, and patient populations depend on interpreting a fragmented and often contradictory body of evidence. Over-trusting a fragile finding, or missing a valid one, can redirect an entire programme.
A validity layer for life science
The lesson from AI's success in mathematics is not that biology should become more like math. It can’t, and it shouldn’t try. Life science is empirical, contextual, and irreducibly complex.
The lesson is that different fields require different forms of verification. The tools that will matter most in life science are not those that generate hypotheses, summarize, or accelerate writing. They are tools that help scientists examine the strength of claims, surface the gaps that matter, and understand how new findings fit into the body of evidence we already have, with a clear eye toward what is established, what is fragile, and what remains unknown.
This is the problem QED Science was built to address: giving researchers, reviewers, and R&D teams a sharper, faster, and more systematic way to evaluate the science they depend on; before publication, and across the existing literature.
Want rigorous, actionable feedback on your own work before it reaches review? Sign up here.
FAQs
How do biological variables affect the reliability of experimental results?
A result can be technically correct and still fail to generalize. The cell line, reagent, animal model, or patient cohort used in a study are more than methodology, they are each part of the finding itself. By changing any one, the result may not hold. This context-dependence is rarely fully specified in published papers, making it one of the most persistent sources of fragility in the life science literature.
What makes preclinical findings difficult to translate into human outcomes?
The history of drug development is full of targets that looked bulletproof in mice or cell lines and collapsed in humans. A finding generated in a preclinical model carries hidden dependencies, for example on the model's genetic background, its immune context, or its signalling environment, that rarely get stress-tested before a target enters the pipeline. When a promising target eventually fails in a human trial, it's often because something upstream was taken on faith that deserved scrutiny.
What are the biggest challenges in evaluating scientific literature at scale?
Volume and unevenness, compounded by the absence of reliable quality signals at the paper level. The standard proxies, including journal rank, citation count, and institutional affiliation are shortcuts to lighten the workload, not guarantees on quality. They accumulate slowly, carry well-documented biases, and say nothing about whether the claims in any individual paper are well-supported by the evidence behind them.
How can AI help researchers assess evidence quality in the life sciences?
By examining the structure of scientific claims. QED Score decomposes each manuscript into its constituent claims and evaluates each against its supporting evidence, surfacing the gaps, unsupported inferences, and methodological weaknesses that prose-level reading tends to miss. Applied at scale, that kind of structured analysis can do in minutes what currently takes expert reviewers months.
Why do promising drug targets sometimes fail during later-stage validation?
This often happens because the original evidence was trusted too early. A finding that looks robust in one context, such as a specific model system, a particular assay, or a narrow patient cohort, gets treated as a generalizable premise and built upon through multiple stages before the assumptions are thoroughly tested. By the time those assumptions are exposed, significant resources have been committed. The problem usually starts in the literature, not the lab.
How can scientists tell whether a published biology paper is trustworthy?
Trusting a paper means trusting its construction, not its credentials. That means asking what was directly demonstrated versus inferred, what assumptions were required, what controls are missing, and whether the conclusions actually follow from the data presented. Journal rank and citation counts are useful orientation — but they're a starting point, not a complete answer.